Deploy a FLIP node in a TRE
Overview
FLIP supports two deployment modes for trust-side services:
On-premise: The FLIP node runs directly on Trust infrastructure (e.g. NVIDIA DGX) with live access to the Trust’s OMOP database and PACS. This is the primary deployment model and provides full access to the Trust’s electronic health records for cohort discovery and imaging data.
Trusted Research Environment (TRE): The FLIP node runs inside a TRE that has been pre-populated with a project-specific subset of data. This mode supports Trusts where governance or infrastructure constraints require data access through a TRE rather than direct on-premise compute.
This guide covers the TRE deployment mode. For on-premise deployment, see Deploy a FLIP node on-prem.
Note
TRE deployment is an alternative to on-premise deployment, not a replacement. The on-premise model remains the recommended approach where Trust infrastructure and governance permit it.
TRE Operator Responsibilities
Deploying FLIP inside a TRE involves coordination between the FLIP team and the TRE operator. The TRE operator is responsible for:
Data provisioning (one-off, per project)
Ingesting the anonymised OMOP dataset and DICOM imaging data into the TRE via the TRE’s standard SOP (after DAC approval).
Provisioning an OMOP PostgreSQL database and a PACS instance (e.g. Orthanc) inside the TRE, with consistent pseudonymisation so records can be linked across them.
Compute provisioning
Providing a host with Docker Engine, Docker Compose, and Docker Swarm support, plus at least one NVIDIA GPU accessible via the NVIDIA Container Toolkit.
Creating the writable host paths the FLIP stack expects under
/opt/flip/(for certs, FL data, OMOP DB volumes, and observability storage – see the Ansible playbook atdeploy/providers/local/site_local_trust.yml).
Container image ingestion
FLIP container images are published to the GitHub Container Registry
(ghcr.io/londonaicentre/*). Because TREs typically block direct pulls from public
registries, images must be ingested through the TRE’s normal file-ingress process. A
common pattern:
Outside the TRE, pull and save each image to a tarball on a workstation that has internet access:
docker pull ghcr.io/londonaicentre/trust-api:<tag> docker save ghcr.io/londonaicentre/trust-api:<tag> -o trust-api-<tag>.tar
Submit the tarballs through the TRE’s file-ingress airlock.
Inside the TRE, load each image into the local Docker daemon:
docker load -i trust-api-<tag>.tar
Note
Other image distribution approaches may be acceptable depending on the TRE – for example, a TRE-internal Docker registry (e.g. Harbor, GitLab, or a registry mirror) that is pre-populated with the required images and reachable from the FLIP host. Coordinate with the TRE operator to pick the option that best fits local policy.
Network policy
Allow outbound HTTPS (port 443) from the FLIP host to the Central Hub FLIP API endpoint — the ALB (e.g.
https://app.flip.aicentre.co.uk).Allow outbound gRPC or HTTP to the FL Server endpoint — a separate host fronted by its own load balancer (the NLB), on its configurable port (e.g.
fl.app.flip.aicentre.co.uk:8002). Allowlisting the API host alone is not sufficient.No inbound ports need to be opened on the TRE perimeter.
Output review
Operating the TRE’s standard output-checking (airlock) process for aggregate metrics leaving the TRE during federated evaluation.
Agreeing a project-specific governance process for federated training if weight egress is in scope (see Deploy a FLIP node in a TRE Use Case 2).
Architecture
In the on-premise model, the FLIP node has direct access to the Trust’s full OMOP database and can pull imaging data live from PACS. In the TRE model, the FLIP node operates on a pre-populated subset of data inside the TRE boundary.
Two communication pathways connect the FLIP node to the Central Hub (hosted on AWS):
Central Hub FLIP API <-> Trust API: Cohort queries, project creation, imaging project management, and status updates.
FL Server <-> FL Client: Model distribution (for evaluation) and model weight exchange (for federated training), orchestrated via the FL framework (e.g. NVIDIA FLARE, Flower).
Both pathways use outbound-only connections, making FLIP compatible with TRE network policies that block inbound traffic.
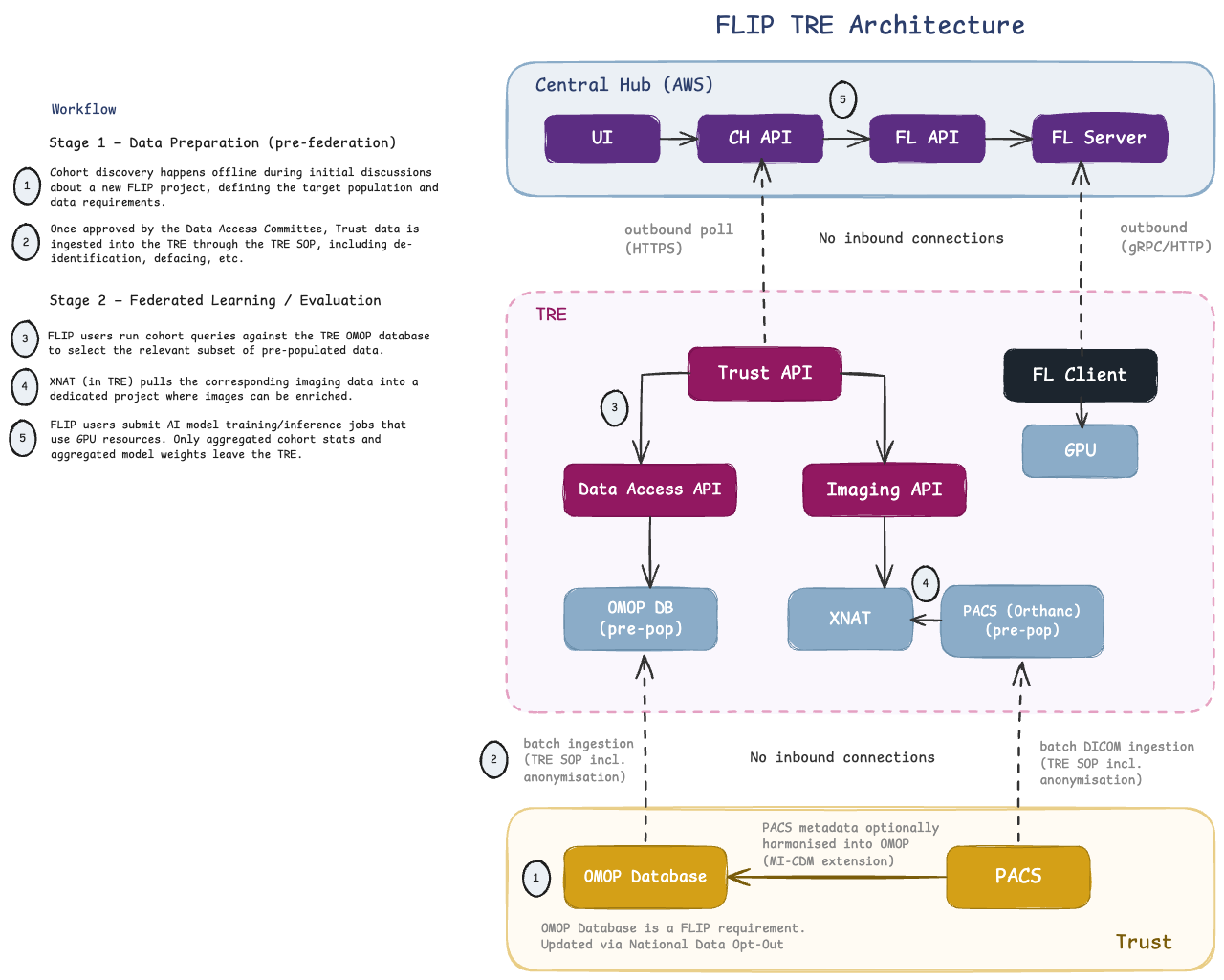
FLIP TRE deployment: outbound-only connections from the FLIP node to the Central Hub.
Communication: Outbound-Only Design
TREs are “walled garden” environments that block inbound network connections. All communication from the FLIP node is initiated from inside the TRE outward to the Central Hub. No inbound ports need to be opened on the TRE side.
FL Server <-> FL Client
The FL channel uses a client-pull model. The FL client initiates all communication – it connects outbound to the FL server, polls for tasks, executes locally, and pushes results back. The FL server never initiates inbound connections to client sites:
In NVIDIA FLARE, the FL client sends
GET_TASKrequests to the FL server and receives tasks in the response, then returns results viaSUBMIT_RESULT.In Flower, each SuperNode acts as a gRPC client connecting outbound to the SuperLink. SuperNodes initiate all requests and do not accept incoming connections.
The TRE need only whitelist outbound gRPC (or HTTP, if using an HTTP/REST transport fallback) to the FL server endpoint.
Central Hub FLIP API <-> Trust API
The Trust API uses an outbound polling model to communicate with the Central Hub. Rather than the Central Hub pushing requests inbound, the Trust API periodically polls the Central Hub for new instructions:
The Trust API calls the Central Hub FLIP API to check for new projects, cohort query requests, and status updates.
When a new project is created on the Central Hub, the Trust API discovers it on its next poll cycle and initiates the local workflow (cohort query against OMOP, imaging pull from PACS into XNAT).
Results (cohort statistics, project status) are pushed outbound from the Trust API to the Central Hub.
The polling loop is implemented in trust/trust-api/trust_api/services/task_poller.py.
Key environment variables (set via .env or Docker secrets):
Variable |
Description |
|---|---|
|
Hub endpoint the Trust API polls for tasks. |
|
Optional self-check. If set and the hub resolves this host’s API key to a different trust id, trust-api exits instead of acting as the wrong trust. Kept in the trust’s kit file. |
|
Per-trust authentication header used on every outbound request. |
|
Symmetric key shared with the hub; used to decrypt task payloads. |
|
Per-trust shared secret used inside the trust for calls between trust-api / imaging-api / fl-client and imaging-api / data-access-api. Never leaves the trust environment. |
|
Polling period in seconds (default: |
Network requirements
The TRE must whitelist outbound connections to two separate endpoints — different hostnames behind different load balancers, so both must be allowlisted:
The Central Hub FLIP API — the ALB (HTTPS, port 443; e.g.
https://app.flip.aicentre.co.uk)The FL Server — the NLB (gRPC or HTTP, configurable port; e.g.
fl.app.flip.aicentre.co.uk:8002)
No inbound ports need to be opened on the TRE.
Data Flow
The key difference between on-premise and TRE deployment is how data enters the FLIP node.
On-Premise Data Flow
FLIP user submits a cohort query on the Central Hub.
The query is federated to all FLIP nodes.
The Trust API queries the full OMOP database and returns aggregated cohort statistics.
Once the project is approved by the Data Access Committee (DAC), the imaging API pulls DICOMs from the Trust’s production PACS into a DICOM staging server (e.g. Orthanc).
XNAT pulls from the staging server into a dedicated project, where images can be enriched.
FL training or evaluation jobs run on the local data.
TRE Data Flow
The TRE model splits the workflow into two phases:
Phase 1: Pre-FLIP (TRE data ingestion)
Before the FLIP user interacts with the system, the Trust’s data team:
Estimates the cohort size against the full Trust EHR (outside FLIP).
Submits and receives DAC approval for the project.
Exports anonymised OMOP records and DICOM imaging data through the TRE’s standard operating procedure (SOP), including anonymisation and defacing where required (e.g. brain CT scans).
Loads the anonymised data into:
An OMOP database inside the TRE.
A PACS instance (e.g. Orthanc) inside the TRE.
Note
The OMOP database and PACS inside the TRE must use consistent pseudonymisation so that clinical records and imaging data can be linked within the TRE.
Phase 2: FLIP workflow (inside the TRE)
Once data is loaded, the FLIP workflow proceeds largely as normal:
When a FLIP project is created on the Central Hub, the Trust API inside the TRE discovers it (via outbound polling) and triggers the local workflow.
The FLIP user runs a cohort query. The
data-access-apiqueries the OMOP database inside the TRE. This selects from the pre-loaded project subset, not the full Trust population.Once the cohort is selected, XNAT pulls DICOMs from the TRE’s internal PACS – using the same C-MOVE/C-GET pattern it would use against a production PACS.
The FLIP user submits FL training or evaluation jobs.
Important
In the TRE model, cohort queries operate on a pre-scoped dataset. The FLIP user can refine and select within the approved data, but cannot discover patients beyond what was loaded into the TRE. Cohort size estimation across the full Trust population must happen before the DAC application, outside FLIP.
Prerequisites
The TRE must provide the following capabilities:
Compute
Docker with GPU support: The FLIP Docker stack requires the NVIDIA Container Toolkit for GPU-accelerated FL training and inference.
Docker Swarm: XNAT services are deployed using Docker Swarm mode. The TRE must support
docker swarm initand overlay networking.Sufficient GPU resources: At minimum, one NVIDIA GPU for inference/evaluation. For FL training, GPU memory requirements depend on the model architecture.
Networking
Outbound HTTPS to the Central Hub FLIP API endpoint on AWS (e.g.
https://app.flip.aicentre.co.uk).Outbound gRPC or HTTP to the FL Server endpoint — a separate host fronted by the NLB (e.g.
fl.app.flip.aicentre.co.uk:8002). If the TRE’s network inspection appliances block HTTP/2 (required for gRPC), most FL frameworks offer HTTP/REST transport fallbacks (e.g. NVIDIA FLARE’s HTTP driver, Flower’s REST transport) that work over standard HTTP/1.1.No inbound connections required.
Data
An OMOP database (PostgreSQL) pre-populated with the project’s anonymised clinical data.
A PACS instance (e.g. Orthanc) pre-populated with the project’s anonymised DICOM imaging data.
Consistent pseudonymisation between OMOP records and DICOM data so they can be linked within the TRE.
Software
Docker Engine (>= 24.0) with Docker Compose (>= 2.40)
NVIDIA Container Toolkit
Python 3.12+
PostgreSQL client libraries (
postgresql-client)Make
Observability
FLIP deploys a log-aggregation stack (Grafana Alloy, Loki, Grafana) alongside the Trust APIs. Alloy scrapes container stdout via the Docker socket, Loki stores logs with 30-day retention, and Grafana provides a pre-provisioned dashboard. The stack runs entirely inside the TRE boundary – no log data is sent to the Central Hub. See Logging Stack for details on configuration, ports, and persistent volumes.
Use Case 1: Federated Evaluation
Federated evaluation is the most TRE-compatible FLIP workflow. A pretrained model is distributed from the Central Hub to FLIP nodes for local evaluation, and only aggregate metrics (AUC, Dice scores, sensitivity, specificity, confusion matrices) are returned.
Why evaluation is TRE-friendly
Model ingress: The pretrained model file is sent from the FL server to the FL client inside the TRE. TREs routinely handle data ingress.
Metrics-only egress: Only aggregate evaluation metrics leave the TRE – not model weights. These metrics are standard summary statistics that TRE output-checking processes (airlocks) are designed to review.
Single egress event: Unlike training, which requires iterative weight exchange across many rounds, evaluation produces a single set of results that can go through standard TRE output review.
No disclosure risk from model weights: Since no locally-trained model weights are exported, there is no risk of patient data leakage through model memorisation or gradient-based reconstruction attacks.
Evaluation data flow
A pretrained model is uploaded to the Central Hub.
The FL server distributes the model to FL clients at each FLIP node (including TRE nodes) via the FL framework’s evaluation workflow.
Each FL client runs inference on local data and computes evaluation metrics.
Only the aggregate metrics are sent back to the FL server.
Note
For TRE nodes, the aggregate metrics leaving the TRE should comply with the TRE’s output-checking policy. Ensure that subgroup analyses on small populations (fewer than the TRE’s minimum cell count, typically 5-10) are suppressed before egress.
Use Case 2: Federated Training
Federated training in a TRE involves iterative exchange of model weights between the FL client (inside the TRE) and the FL server (on the Central Hub). This is more complex from a governance perspective than evaluation.
Training data flow
The FL server sends the initial global model to all FL clients.
Each FL client trains locally for a number of local rounds.
The FL client sends updated model weights back to the FL server.
The FL server aggregates weights from all clients (e.g. via FedAvg) and distributes the updated global model.
Steps 2-4 repeat for the configured number of global rounds until convergence.
Warning
Model weight egress is an open governance problem
Federated training requires model weights to leave the TRE on every global round. This creates a tension with TRE governance:
TRE output-checking processes are designed for human review of statistical outputs (tables, charts). Model weights are opaque numerical tensors that cannot be manually inspected for disclosure risk.
Model weights can encode patient information. Research has demonstrated membership inference attacks, gradient inversion attacks, and model memorisation that can reconstruct training data from model parameters.
No UK TRE currently permits automated egress of model weights through standard output-checking processes.
Iterative exchange compounds the problem – a typical FL training run involves tens to hundreds of global rounds, each requiring model weights to cross the TRE boundary.
Mitigations for training egress
Several technical mitigations can reduce the disclosure risk of model weight egress. These do not eliminate the governance challenge but may support a risk-based approval process:
Differential privacy (DP-SGD)
FL frameworks provide differential privacy filters that add calibrated noise to model weight updates before they leave the client (e.g. NVIDIA FLARE’s privacy filters, Flower’s central and local DP strategies with adaptive clipping). DP provides formal mathematical bounds on privacy leakage (the epsilon parameter), but clinically useful DP budgets (epsilon ~ 10) do not prevent all attacks, while strict guarantees (epsilon < 1) can significantly degrade model performance.
Secure aggregation
Some FL frameworks support homomorphic encryption (e.g. NVIDIA FLARE’s TenSEAL integration using the CKKS scheme) which allows weight aggregation on encrypted values, so the FL server never sees individual client weights. This prevents a curious aggregation server from inspecting any single client’s contribution.
Gradient clipping
FL frameworks typically provide gradient clipping filters that bound the contribution of any single training example to the model update, limiting the information any one patient’s data can encode in the shared weights.
Current recommendation
For TRE deployments where federated training is required, work with the TRE operator and the Data Access Committee to establish a project-specific governance agreement covering model weight egress. This should specify:
The privacy-enhancing technologies to be applied (DP, secure aggregation).
The DP budget (epsilon) and clipping parameters.
Audit and logging requirements for all egress events.
Whether the TRE airlock process needs to be adapted for automated weight review (e.g. using SACRO-ML tools for post-hoc attack simulation).
This is an active area of development in the UK TRE ecosystem. DARE UK’s TREvolution programme is working toward standardised egress policies for federated learning workflows.
Differences from On-Premise Deployment
Aspect |
On-Premise |
TRE |
|---|---|---|
OMOP database |
Live sync from Trust EHR, updated via National Data Opt-Out |
Pre-populated with anonymised project subset |
PACS |
Trust production PACS (live pull) |
Orthanc inside TRE, pre-populated with anonymised DICOMs |
Cohort query scope |
Full Trust population |
Project-specific subset only |
Cohort discovery |
Via FLIP (step 1 of workflow) |
Outside FLIP, before DAC application |
Data freshness |
Live / near-real-time |
Snapshot at time of TRE data load |
Networking |
Outbound-only (HTTPS + gRPC/HTTP to Central Hub) |
Outbound-only (HTTPS + gRPC/HTTP to Central Hub) |
Central Hub <-> Trust API |
Poll (outbound) |
Poll (outbound) |
Evaluation egress |
Aggregate metrics via FL channel |
Aggregate metrics via FL channel (TRE airlock review) |
Training egress |
Model weights via FL channel |
Model weights via FL channel (governance approval required) |
GPU access |
Trust-managed DGX / GPU servers |
TRE-provided GPU compute with NVIDIA Container Toolkit |
UK TRE Federation Landscape
Deploying federated learning across TREs is an active area of development in the UK. The DARE UK TREvolution programme (UKRI-funded, launched 2025) is developing standardised federation capabilities across UK TREs, including reference architecture, semi-automated output checking, and federated analysis. TREvolution introduces Patterns and Weaves – configurable combinations of analysis type, technology services, and egress rules. The first Weave is the Five Safes TES, which adopts the GA4GH Task Execution Service (TES) standard as the basis for interoperability, enabling TREs to receive and execute standardised workflow tasks through a common API. Related projects include TRE-FX (which developed the Five Safes RO-Crate packaging format for governance metadata around workflow outputs) and SACRO (which provides semi-automated output checking tools, including an ML extension for attack simulation against trained models).
FLIP’s TRE deployment model aligns with this direction. As TREvolution matures, its Patterns framework could formalise different egress rules for different federated workflows (e.g. metrics-only for evaluation vs. DP-protected weights for training), providing the governance pathway that FLIP’s TRE training use case currently lacks.
GPU Resource Management
TRE environments may offer the ability to dynamically provision and release GPU resources based on workload requirements. Unlike on-premise deployments where dedicated GPU hardware (e.g. DGX systems) is always available, cloud-based TREs can scale GPU compute on demand.
FLIP’s architecture supports this: some trust-side services (e.g. the data-access-api
for OMOP queries) do not require GPU, while the FL client only needs GPU resources during
active training or evaluation jobs. TRE operators may wish to:
Provision GPU instances only when FL jobs are scheduled, and release them between jobs.
Periodically re-evaluate GPU resource allocation based on model size, training duration, and concurrent workload.
Use spot/preemptible GPU instances for evaluation jobs (which can be restarted) and reserved instances for training jobs (which benefit from continuity).
The FLIP Docker Compose configuration separates GPU-dependent services (FL client) from non-GPU services (Trust API, data access API, XNAT), making it straightforward to run them on different compute tiers within the TRE.